Search -- Informed Search - A* and Heuristics
无信息搜索(如UCS)虽然能保证找到最优解,但它像是在黑暗中摸索,会向所有方向均匀扩展,效率低下。如果我们能给智能体一些关于“目标大概在哪个方向”的提示,搜索就能变得更高效。这种提示就是启发式 (Heuristics)。
启发式 (Heuristics)
启发式是一个函数 h(n),它接收一个状态 n 作为输入,输出一个对“从状态 n 到达目标的剩余成本”的估计值。
启发式的来源:松弛问题 (Relaxed Problem)
好的启发式通常来自于对原问题的“松弛” (Relaxed Problem)
松弛问题是通过移除原问题的一些约束得到的简化版问题。下面以吃豆人寻路示例:
原问题:吃豆人必须在迷宫中穿行,不能穿墙。
约束:不能穿墙。
松弛:我们移除“不能穿墙” 这个约束。
松弛问题:在一个没有墙的开放网格中,从A点到B点的最短路径是什么?
松弛问题的精确解:这个解就是曼哈顿距离 (|x₁ - x₂| + |y₁ - y₂|) 。
原问题比松弛问题有更多的约束(比如有墙),所以在原问题中从 n 到目标的真实最短路径成本 h*(n),必然大于或等于在松弛问题中的最短路径成本。
因此,松弛问题的解 h(n) 永远不会高估真实成本,即 h(n) ≤ h*(n)。这正是我们稍后会讲到的可采纳性 (Admissibility) 的关键特征。
综上所述, 对应吃豆人问题, 曼哈顿距离 (|x₁ - x₂| + |y₁ - y₂|) 是在原问题的松弛版(无墙迷宫)中的精确解,因此它可以作为原问题(有墙迷宫)的一个估计值。这种通过简化问题来获得估计值的方法,是设计启发式函数的一条重要原则。
两种有信息搜索策略
有信息搜索策略 (Informed Search) 是基于启发式信息来指导搜索的策略。
贪婪/贪心搜索 (Greedy Search)
这是一种完全由启发式驱动的“短视”策略。它在选择下一个要扩展的节点时,只看 h(n) 的值,即它认为“离目标最近”的那个 。
前沿表示:和UCS一样使用优先队列,但优先级由 h(n) 决定 。
它的特点是不完备且不最优:贪婪搜索完全不考虑已经走过的路径成本 g(n)。它可能会被一个看似离目标很近、但实际上需要绕远路的陷阱所吸引,从而找不到解,或者找到一个成本很高的解。
A* 搜索 (A* Search)
A* 搜索结合了 UCS 和贪婪搜索的优点,它选择估计的总成本 f(n) 最低的节点进行扩展, 这个函数同时考虑了过去和未来 。
这里的f(n) = g(n) + h(n)
g(n):从起点到当前节点的实际已知成本(UCS的部分)。
h(n):从当前节点到目标的估计剩余成本(贪婪搜索的部分)。
A* 搜索的特点是完备且最优(在特定条件下), 选择的是估计总路径成本最低的节点, 被誉为“集大成者”,因为它既考虑了已付出的代价(通过 g(n)),又具有前瞻性(通过 h(n)),因此在效率和最优性上取得了完美的平衡。
启发式的性质
A* 搜索的完备性和最优性并非无条件的,它严重依赖于启发式函数 h(n) 的质量。
可采纳性 (Admissibility)
一个启发式是可采纳的,当且仅当它从不高估到目标的真实成本。即对于所有节点 n,0 ≤ h(n) ≤ h*(n),其中 h*(n) 是从 n 到目标的真实最低成本。
可采纳性是保证 A* 树搜索 (Tree Search) 最优性的关键条件。
一个“乐观”的启发式函数是可采纳的, 同时一个好的启发式函数也要在足够乐观的同时尽可能客观(即启发式函数要在较小的里面挑选更大的)。它可能会告诉你“目标(启发函数值)比实际更近”,但绝不会告诉你“目标比实际更远”。这种乐观使得A*算法不会过早地放弃一条可能通往最优解的、当前看起来成本较高的路径。
一致性 (Consistency)
一致性是一个更强的条件。它要求启发式不仅不能高估到目标的总距离,也不能高估任意一步的成本。对于任意节点 A 和其子节点 C,从 A 到 C 的启发式成本差,不应大于 A 到 C 的实际行动成本 。数学上表示为:h(A) − h(C) ≤ cost(A, C) 。
一致性是保证 A* 图搜索 (Graph Search) 最优性的关键条件 。
支配性 (Dominance)
如果对于所有节点 n,启发式 ha(n) ≥ hb(n),那么我们说 ha 支配 hb。
在所有可采纳的启发式中,值越大的(即越接近真实成本 h*(n) 的)启发式越好,因为它能提供更精确的引导,让 A* 扩展更少的节点。
组合启发式的思想:多个可采纳(或一致)的启发式的最大值,仍然是一个可采纳(或一致)的启发式,并且它会支配所有单个的启发式。这为我们构建更好的启发式提供了一种实用的方法。

图搜索 (Graph Search)
在之前的笔记中,我们讨论的算法(DFS, BFS, UCS, A*)都可以在两种模式下运行:树搜索模式和图搜索模式。
树搜索 (Tree Search):它不检查是否重复访问了同一个状态。
图搜索 (Graph Search):这是对树搜索的优化。它会记录所有已经访问并扩展过的状态,以避免重复工作。
从中可见, 树搜索有两个严重的问题,尤其是在状态空间图包含环路 (cycles) 或多条路径到达同一状态时:
无限循环:如果状态空间中有环(例如 A -> B -> C -> A),一个简单的树搜索(特别是DFS)可能会永远地在这个环里打转,永远找不到解,导致算法不完备 。
冗余工作:即使没有环路,也常常存在多条不同的路径可以到达同一个状态。树搜索会把每一条路径都当作一个全新的节点来探索,导致对同一个状态及其后续路径进行大量重复计算,极大地浪费时间 。
而图搜索通过在算法中维护一个额外的集合,通常称为 reached 或 closed set(已达集合)来优化这个问题, 其步骤如下: 1. 初始化一个空的 reached 集合。
- 当算法从前沿 (frontier) 中取出一个节点准备扩展时,首先检查该节点所代表的状态是否已经在 reached 集合中。
如果在,则跳过这个节点,不进行扩展,直接进入下一次循环。
如果不在,则将该状态加入 reached 集合,然后正常扩展该节点,将其子节点加入前沿。
通过这个简单的机制,图搜索保证了每个状态最多只会被扩展一次,从而避免了无限循环和冗余计算。
然而, 图搜索的一个附带问题是,即使使用可采纳的启发式,它也往往会破坏
A* 的最优性, 例如下图: 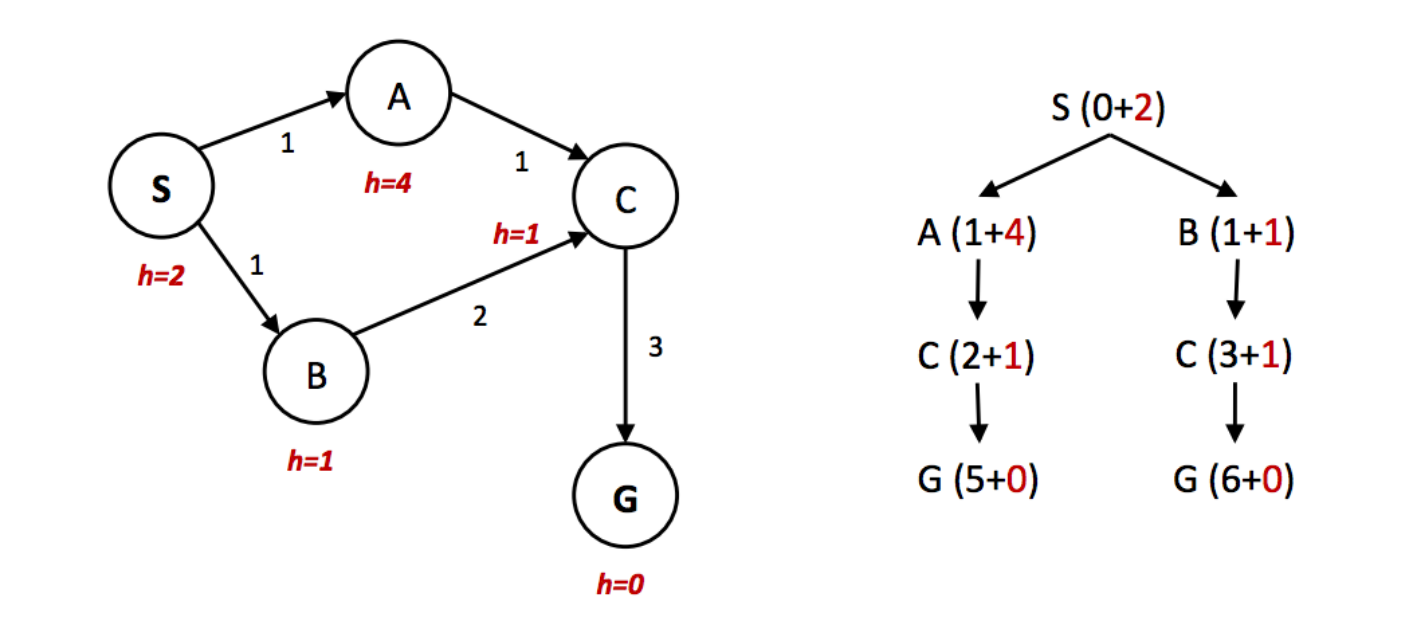
在上面的例子中,很明显最佳路径是遵循 S → A → C → G,总路径成本为 1+1+3=5。通往目标的其他唯一路径 S → B → C → G 的路径成本为 1+2+3=6。然而,由于节点 A 的启发式值远大于节点 B 的启发式值,节点 C 首先沿着第二条次优路径作为节点 B 的子节点被展开。然后它被放入”已到达”集合中,因此 A 图搜索在它作为节点 A 的子节点访问时未能重新展开它,所以它永远找不到最优解。因此,为了在 A 图搜索下保持最优性,我们需要比可采纳性更强的性质, 也就是之前提到的一致性.
这也为我们设计更加严格的启发式函数提出了挑战
下图为一个启发式函数的设计示例
