Search -- Local Search
局部搜索 (Local Search)概述
与前几讲(如A*搜索)不同,局部搜索算法解决的是另一类问题。在之前的搜索中,我们不仅关心是否能到达目标,还关心如何到达,即找到一条完整的路径 。
然而,在很多问题中,我们只关心最终的解决方案状态,而不关心到达该状态的具体步骤 。
局部搜索 (Local Search)
就是为这类问题设计的。它不维护从起点开始的路径,而是从一个完整的、可能是随机的配置(状态)开始,然后通过一系列局部的、微小的修改,逐步改进这个配置,直到找到一个满足约束或优化了某个目标函数
(objective function) 的状态 。 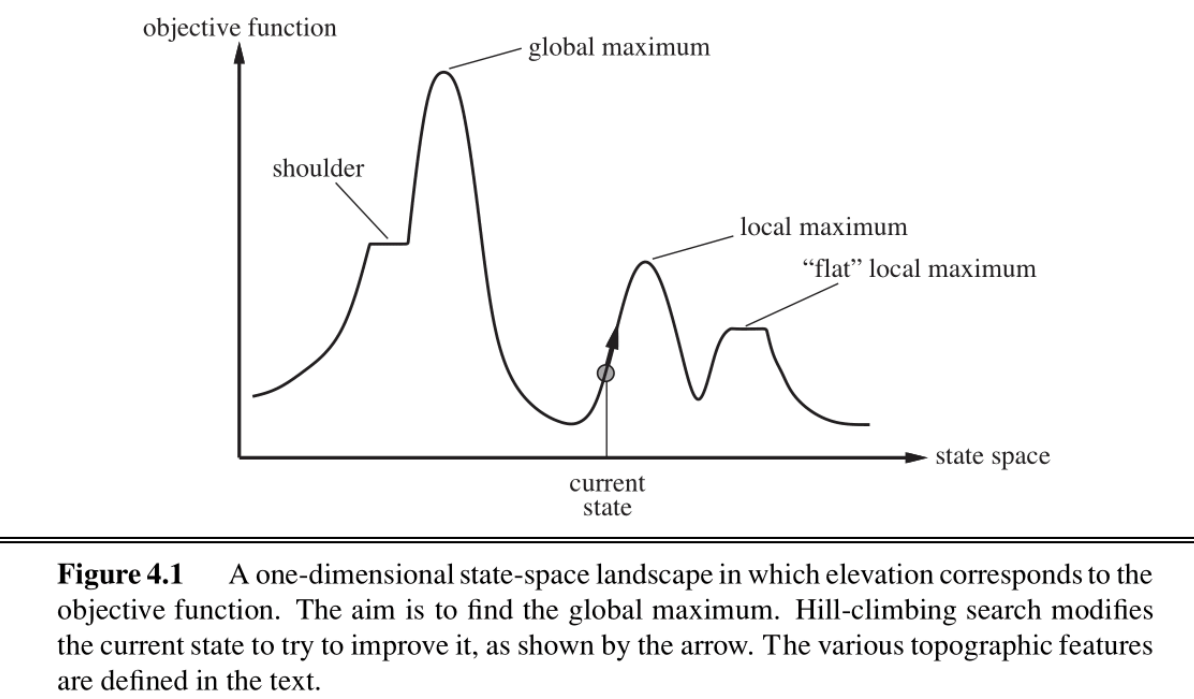
爬山算法 (Hill-climbing)
这是最基础的局部搜索算法。它非常“贪婪”,在当前状态下,它会审视所有邻近的状态,并选择那个能使目标函数值提升最大的方向移动一步 。这个过程也被称为最陡峭上升 (steepest-ascent)。
它不维护搜索树, 只保留当前的状态,内存开销极小 。
它的缺点是容易陷入困境:由于其“贪婪”的本性,一旦到达一个局部最大值,它就会因为周围没有更高的点而“卡住”,错误地认为已经找到了顶峰 。同样,它也可能在“高原”上迷失方向 。
其伪代码如下
1 | function HILL-CLIMBING(problem) returns a state |
其变体与改进有如下两种:
随机爬山法 (Stochastic Hill-Climbing):不是选择最好的上坡方向,而是在所有可能的上坡方向中随机选择一个。这增加了探索性,有时能找到更好的解,但通常需要更多步数 。
随机重启爬山法 (Random-Restart Hill-Climbing):这是解决局部最大值问题的最有效方法之一。它多次从一个随机生成的初始状态开始运行爬山法。如果一次搜索陷入了局部最大值,就放弃它,重新开始一次新的搜索。这个方法在理论上是完备的,因为只要有足够多的重启次数,总有一次会从全局最大值的“山坡”上开始攀登 。
模拟退火 (Simulated Annealing)
模拟退火是一种更智能的算法,它试图结合爬山法的效率和随机游走的完备性 。它的核心思想是:在搜索初期,允许一些“坏”的移动(即走向目标函数值更低的状态),以帮助算法“跳出”局部最大值的陷阱 。
算法机制:
接受好移动:如果一个随机选择的移动能提升目标函数值,则总是接受它 。
概率性接受坏移动:如果移动会降低目标函数值,则以一定的概率接受它 。
温度 (Temperature):这个接受概率由一个叫做“温度”的参数 T 控制。在开始时,T 很高,接受“坏”移动的概率也较高,算法有更多的探索性。随着时间的推移,T 会根据一个“退火时间表 (schedule)”逐渐降低,使得算法越来越倾向于只接受“好”的移动,最终稳定在某个最大值上 。
理论保证:如果温度下降得足够慢,模拟退火理论上能以趋近于1的概率找到全局最优解 。
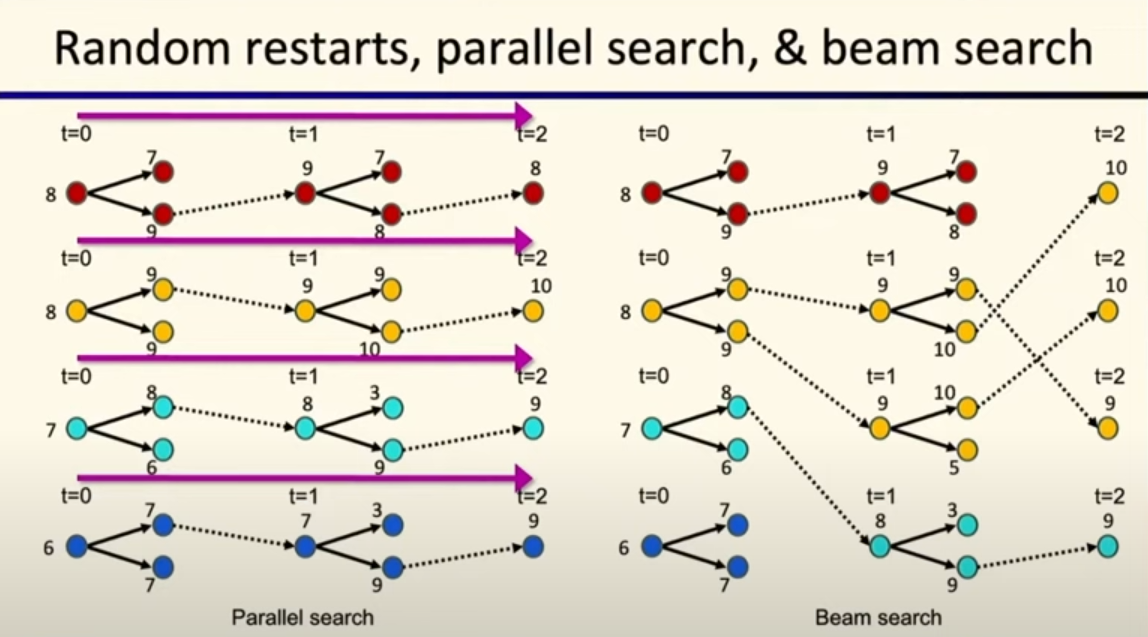
局部束搜索 (Local Beam Search)
这是爬山法的一个变种,但它不是只维护一个当前状态,而是同时维护 k 个状态(称为一个“束”或“线程”)
它不是简单地并行运行 k 次独立的爬山法 。在每一步,算法会生成这 k 个状态的所有后继状态,然后从这些所有的后继状态中,选择最好的 k 个作为下一代的新状态束 。
这种机制允许信息在不同的搜索路径之间共享。如果某个状态(线程)进入了一个很有希望的区域,它的优良后代就有可能被选中,从而“吸引”其他搜索力量向这个区域集中 。
遗传算法 (Genetic Algorithms)
遗传算法是一种受生物进化论启发的局部搜索技术,可以看作是局部束搜索 (Local Beam Search) 的一种高级变体。
与传统的爬山法或模拟退火不同,遗传算法不是只维护一个或少数几个状态,而是维护一整个种群 (Population) 的状态。这个种群会像生物世界一样,经历一代又一代的进化,通过选择 (Selection)、交叉 (Crossover) 和变异 (Mutation),最终演化出适应环境的、高质量的解决方案。
其关键概念如下: - 个体 (Individual):种群中的每一个成员,代表了问题的一个完整解(状态)。
基因编码 (Encoding):每个个体需要被编码成一个字符串,这就像生物的DNA。讲义中以8皇后问题为例,一个解决方案(棋盘布局)被编码为一个8位数字串,如 24748552,其中第 i 个数字代表第 i 列上皇后的行号。
适应度函数 (Fitness Function):这就是局部搜索中的目标函数。它用来评估每个个体的“优劣”程度。对于8皇后问题,适应度函数计算的是不互相攻击的皇后对的数量。一个完美的解,其适应度为 (8*7)/2 = 28。
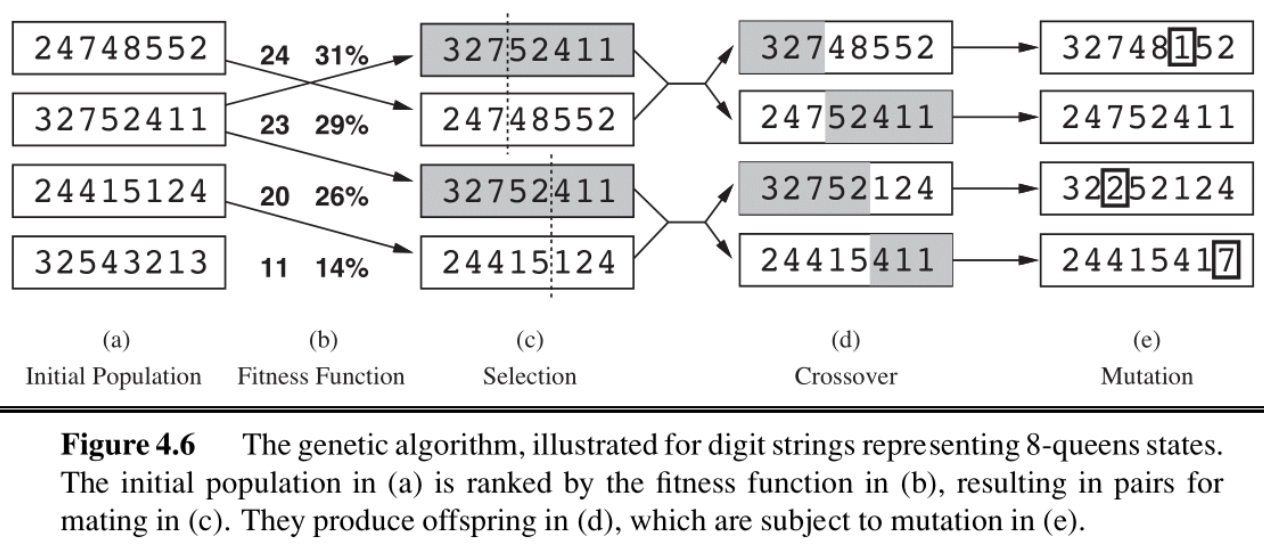
下面以上图的八皇后问题来展示遗传算法的核心流程: - 步骤 (a): 初始种群 (Initial Population) - 算法从一个随机生成的、包含 k 个个体的种群开始。这为进化提供了最初的“基因库”。 - 图中展示了4个随机生成的8皇后棋盘布局的编码。
步骤 (b): 适应度评估 (Fitness Function)
使用适应度函数评估种群中每个个体的“好坏”。这个评价值决定了个体在下一轮繁殖中被选中的概率。
图中计算了4个个体的适应度(24, 23, 20, 11),并根据适应度高低计算出它们被选中的概率(31%, 29%, 26%, 14%)。
步骤 (c): 选择 (Selection)
模拟“适者生存”的过程。适应度越高的个体,越有可能被选中作为“父母”来繁殖下一代。
根据(b)中的概率,进行了4次随机选择,选出了两对“父母”。注意,适应度较高的个体 32752411 被选中了两次,而最低的 32543213 未被选中。
步骤 (d): 交叉 (Crossover)
这是遗传算法最核心、最强大的环节。算法为每一对父母随机选择一个交叉点,然后将它们的“基因串”在该点切开并交换后半部分,从而创造出两个全新的子代。
为什么交叉如此重要? 它允许在不同父代中独立进化出的优良“基因片段”(即解决方案的好的局部结构)被组合在一起,从而有潜力创造出远优于其父代的全新解决方案。
父代 32752411 和 24748552 在第3位后交叉,生成了子代 32748552。这个子代继承了第一个父代的前3个皇后位置和第二个父代的后5个皇后位置。

步骤 (e): 变异 (Mutation)
在子代生成后,其基因串上的每一个位置都有一个很小的概率发生随机突变。
为什么需要变异? 变异为种群引入了新的基因多样性,有助于防止算法过早收敛到某个局部最优解,增加了跳出陷阱、找到全局最优解的可能性。
图中,有三个子代的基因发生了突变(方框标出的数字)。
这个“评估 -> 选择 -> 交叉 -> 变异”的循环会不断重复,直到找到一个满足条件的解,或者达到预设的迭代次数。